Reading List
This is a feed of links I've run across and found interesting or noteworthy. The images, content and opinions in them are owned by their respective authors.
How AI will change software engineering – with Martin Fowler
Martin Fowler - youtu.be
Fowler discusses AI's impact on software engineering, emphasizing non-deterministic coding, the need for rigorous testing of LLMs, and the enduring importance of refactoring and core engineering skills.
AI, software engineering, Martin Fowler, refactoring, LLM
AWS re:Invent 2025 - Introducing AI driven development lifecycle (AI-DLC)
AWS Events - youtu.be
AI-DLC integrates AI into the software lifecycle, enhancing velocity and quality while ensuring human oversight through three phases: Inception, Construction, and Operations.
AI, software engineering, development lifecycle, collaboration, AWS
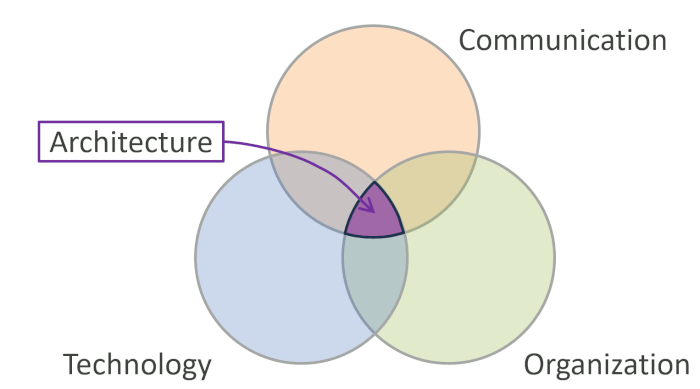
Being an architect isn’t the sum of skills. It’s the product.
Gregor Hohpe - architectelevator.com
Architecture blends technical and non-technical skills, emphasizing that success isn't just about expertise but also about understanding broader contexts.
architecture, skills, IT, technical, non-technical
The New Best Scheduling Library in .NET
Nick Chapsas - youtu.be
Learn about TickerQ, the superior scheduling library in .NET that addresses issues found in Quartz and Hangfire.
TickerQ, .NET, scheduling library, C#
The Coolest Feature of .NET 10 is Here
Nick Chapsas - youtu.be
Discover the new Server Sent Events feature in .NET 10 for efficient server-client communication.
C#, .NET, Server Sent Events, software engineering
Build better web apps with Blazor in .NET 10
dotnet - youtu.be
Discover Blazor's enhancements in .NET 10 for secure, responsive web apps, with improved diagnostics, performance, and user-friendly features like Hot Reload and Entra ID support.
Blazor, .NET 10, web development, performance improvements, Hot Reload, Entra ID
Performance Improvements in .NET 10
Stephen Toub - youtu.be
.NET 10 features significant performance optimizations, enhancing speed and efficiency for various applications without code changes.
performance, .NET 10, optimizations, speed, application development
How to upgrade .NET application to .NET 10
Remigiusz Zalewski - youtu.be
Step by step guide for upgrading your .NET application to .NET 10, including dependency checks and compatibility fixes.
upgrade, .NET 10, EF Core, migration, dependencies

Visual Studio Code adds multi-agent orchestration
Unknown - share.google
Visual Studio Code 1.107 enables developers to combine GitHub Copilot with custom agents, allowing work delegation across local, background, and cloud environments.
Visual Studio Code, GitHub Copilot, multi-agent orchestration
Getting Started with Channels in .NET
Nick Chapsas - youtube.com
Nick explains the underrated Channels feature in .NET every developer should know. Check it out for free courses and more!
C#, .NET, Channels, programming